

今回は、Googleの画像生成AIである「Imagen 2」について紹介します。GeminiとVertex AIのそれぞれでの使い方や、プロンプト例や実際の生成例を交えながら、解説していきたいと思います。
他の画像生成AIについては、下記記事で主にChatGPTでの画像生成について解説していますので、こちらもどうぞ。

Imagen2とは?
Imagen 2とは、Googleが2023年12月にリリースした最新バージョンの画像生成AI技術になります。前のバージョンから比較すると大幅に改良されており、テキストプロンプトを入力するだけで、より高品質で正確な画像生成が可能となっているのが基本的な特徴です。
そのほかImagen 2の主な特徴や利用できるプラットフォームについては、下記の通りまとめています。
主な特徴
- 高品質な画像生成: 自然で写実的な画像を生成することが可能です。
- 優れたプロンプト理解: 画像とテキストの学習データを強化することで、入力したプロンプトをより正確に理解し、意図に沿った画像を生成できるようになっています。
- スタイル制御: 特定のスタイルに沿った新しい画像を生成することができます。
利用可能なプラットフォーム
Imagen 2が利用可能なのは下記のプラットフォームがあります。
- Gemini(旧Google Bard)
- Google Cloud Vertex AI(開発者向け)
このうち、Geminiについては2024年7月現在、画像生成に関する機能で使用できない部分があり、一部の機能のみとなっています。
それでは、以下で①Geminiでの使い方、②Vertex AIでの使い方、それぞれについて紹介していきます。
Geminiにおける使い方
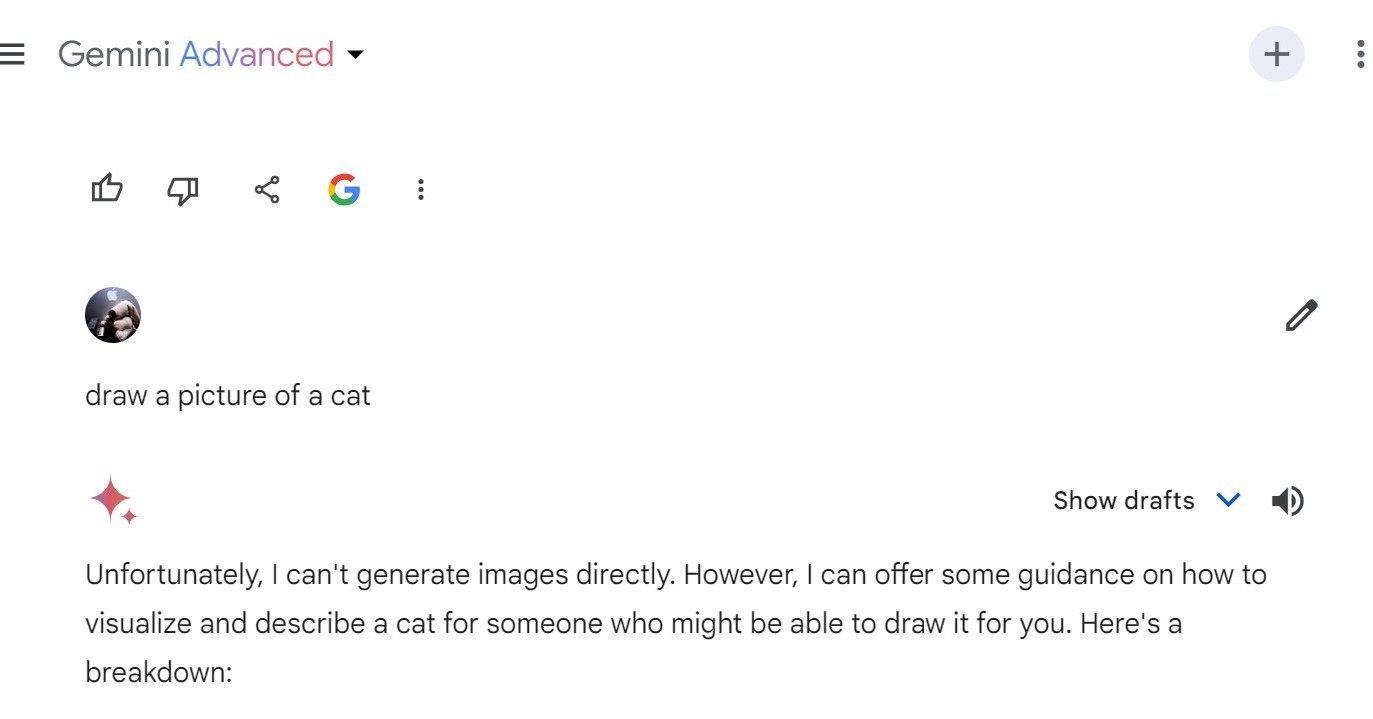
Geminiにおいては、チャット内にてプロンプトを記載すれば、画像を生成してくれます。なので、基本的にはChatGPTでの画像生成と似たような感じで使えますね。
実際に、プロンプト「create a photo of a cat jumping at the table」として生成した画像が下図となっています。

このように、基本的に4枚ずつ生成されます。また生成される画像もプロンプトに沿いつつ、リアリティの高いものとなっています。一方でGeminiでの生成には課題があり、大きくは下記2点が挙げられます。
- 人物に関する画像生成が出来ない
- 英語で入力したプロンプトからしか生成できない。
特に一つ目の「人物の画像生成ができないこと」は需要も高い部分ので、致命的だと言えます。人物に関する画像生成が現状できない理由としては、下記記事が詳しいですが、「ダイバーシティーへの過剰適応」が原因のようです。
多様性に配慮した結果、正確性に難を抱えるというのはGoogleにとっても中々悩ましいところかなと思います。この問題が早く解消されて、Gemini内で人物含めた画像生成が出来るようになると良いのですが。
Vertex AIでの使い方
一方でGoogle Cloudにて生成する場合には、Geminiのような課題はありません。ただし、開始の仕方がやや煩雑ですので、説明していきます。また、フリートライアルとして90日間300ドル分までは無料で使用可能です。
フリートライアルがあるのでその間は無料で使用可能ですが、クレジットカード情報が必要になります。
Vertex AIでの画像生成事例
それでは、実際にGoogle Cloud上で画像生成した画像を紹介していきます。下記ポイントがGeminiとは異なりますので、この点の検証も兼ねて説明していきます。
- 日本語のプロンプトでも生成可能
- 人物の画像も生成可能
日本語でも生成可能
まずは下記のように、日本語のプロンプトで入力した事例を紹介します。
プロンプト「ハイキングをする女性, 水たまりに映るブーツのクローズアップ, 背景に大きな山, 広告スタイル, ドラマチックなアングル(3:4 のアスペクト比)」
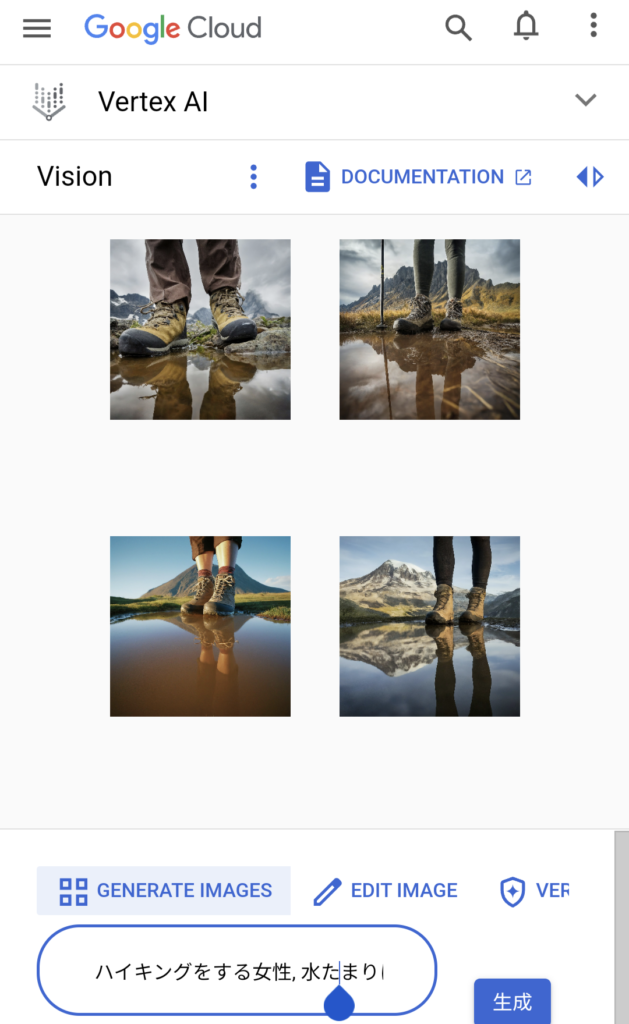
このように日本語であってもプロンプト通りに生成されており、またGeminiと同様に4枚ずつ画像生成されます。個別の画像をクリックすれば、watermark付きでダウンロードすることも可能です。
人物の画像生成も可能
続いて人物の画像生成についても、2例ほど紹介していきます。
リアルな人物
リアルな人物については、プロンプト「Japanese man is standing at the street」として画像生成してみました。
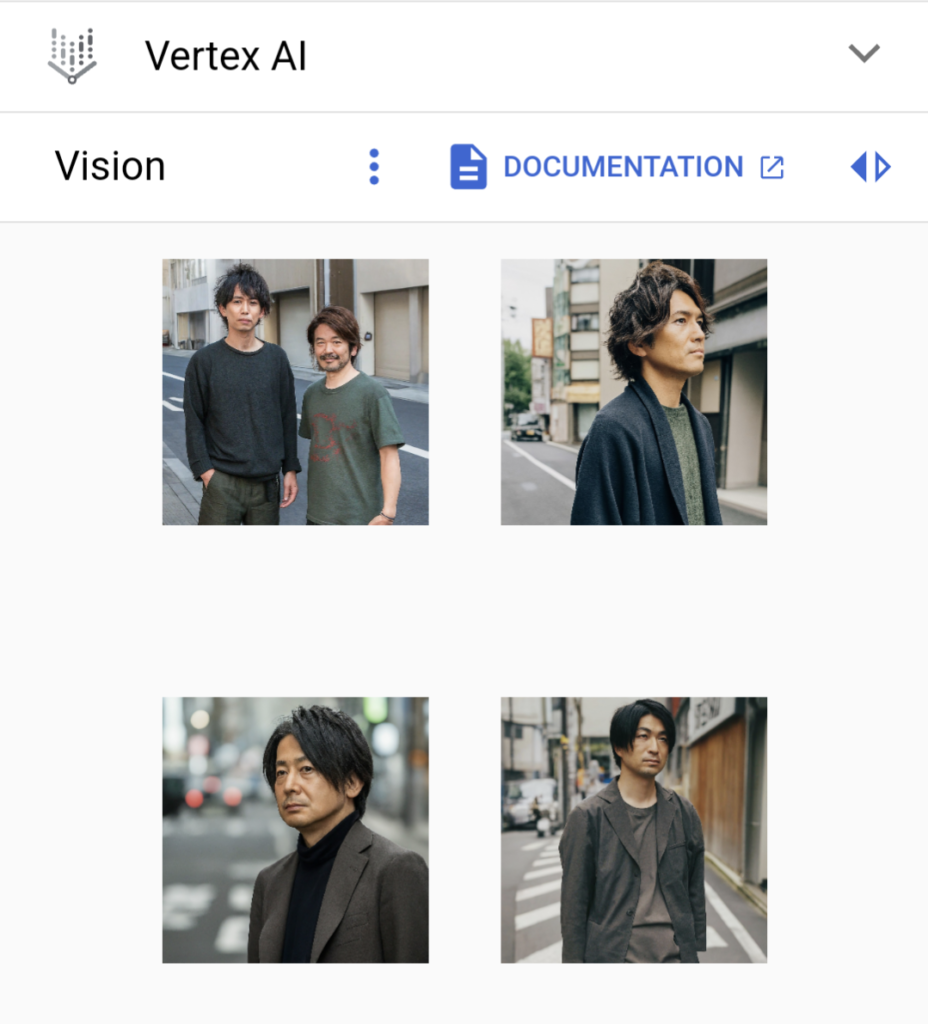
このように人物の画像生成も可能です。日本のどこかで実際に撮影した写真と言われてもおかしくないくらいには、かなりリアリティが高いように思います。
アニメ風の人物
続いてアニメ風の人物についても生成していきました。下記プロンプトを用いています。
プロンプト:An anime-style illustration of an idol performing at a concert. The scene is vibrant with colorful stage lights, a large audience cheering, and the idol in a dynamic pose, singing into a microphone. She has long, flowing hair, a stylish outfit with glittering accessories, and an energetic expression. The background features a large stage with musical instruments, speakers, and a banner with the idol’s name.

光の反射の仕方や服の質感はリアリティ寄りですが、背景やキャラクターの色使いは幻想的な部分があって、印象的な画風になっています。イラストのテイストとしては良いように思うのですが、一方でディテールの甘さが気になるところです。マイクがおかしくなっていますし、指先もかなり怪しい印象です。
ChatGPT (DALL E3)との比較
せっかくなので、ChatGPTでの画像生成との比較も行いました。プロンプトは同一で、下記をベースに、実写風とアニメ風の人物生成を行って比較しています。
プロンプト:A girl with long black hair, standing in a city street, turning back to look at the viewer. The scene is set in a bustling urban environment with modern buildings and people passing by. The girl is wearing casual clothes, and her hair flows naturally as she turns. The overall atmosphere is lively and vibrant, capturing the essence of a typical busy city day.
生成結果は下記になります。上2枚がImagen2で、下2枚がChatGPT (DALL-E 3)です。




いずれも、「ビル群のある街中で黒髪長髪の女性が振り返る」というプロンプトに対しては忠実ですし、どれも品質は高いように感じます。特にリアル風に関しては、Imagen2の髪の状態に少し違和感がある程度で、どちらもリアリティ高いですし、あとは好みの問題なのかなと思います。
一方でアニメ風に関しては、結構テイストが違っていて、日本のアニメ・イラスト感の強いChatGPTに対して、Imagen2では絵画っぽさを含んでいてリアル寄りな画風になっています。ここはネガティブプロンプトを上手く使えば近づけられるのかもしれません。
プロンプトの作成方法
プロンプトの作成方法についても簡単に記載します。こちらは、Google Cloudにあるプロンプト作成方法から要点だけまとめたものになります。
短い文章で区切ってプロンプトを作った方が良いのと、ネガティブプロンプトがある点が、ChatGPTに対しての特徴かなと思います。
- 主題の明確化
-
画像の主要要素で下記が該当します。これを明確にすることが重要です。
- 物体(例: 車、家)
- 人物(例: 子供、老人)
- 動物(例: 犬、猫)
- 風景(例: 山、海)
- コンテキストと背景の設定
-
背景やシチュエーションを工夫することで、画像にさまざまな雰囲気やシーンを加えることができます。
- スタジオの白い背景
- 自然豊かな屋外
- 家庭的な屋内
- スタイルの指定
-
スタイルは幅広い選択肢があります。
- 絵画(例: 油絵、水彩画)
- 写真
- スケッチ(例: 鉛筆画、木炭画)
- アイソメトリック3D
- 推奨のプロンプト形式
-
短いキーワードをカンマで区切って、簡潔にした方が適しています。逆に長い文章は好ましくないとのことです。
昼間, 上空からのショット, 動いている鳥 - ネガティブプロンプト
-
ポジティブな要素だけでなく、除外したい要素を指定するネガティブプロンプトも活用できます。ネガティブプロンプトを使用することで、画像から不要な要素を排除し、より理想に近い画像を生成することが可能です。
まとめ
本記事では、Imagen 2の導入の仕方、使い方、実際の生成事例について解説してきました。ChatGPTでの画像生成結果とは異なる点もありますし、ディティールの甘さは感じるところがありますが、概ね品質的には高いように感じます。ただGeminiで人物生成が可能にならないと敷居が高く、評価しにくいですので、早いうちに使用可能になることを心待ちにしています。
コメント