

最近のAI技術の進歩は本当に早いのですが、未だ避けては通れないの問題の一つが「ハルシネーション」です。本記事では、「ハルシネーション」とは何なのかの説明と、ChatGPT 4oになってどこまで改善されてきたのかについて、具体的に解説していきます。
ハルシネーションとは、「AIが嘘をつく現象のこと」
ハルシネーションとは元々「幻覚」を意味する言葉で、特に生成AI界隈においては、AIが事実ではない情報や現実に存在しない内容を生成する現象のことを言います。わかりやすく言うと、AIが「夢を見ている」ような状態で、実際には起こっていないことや間違った情報を示すことです。
例えば、AIに「日本の首都はどこ?」と質問したときに、仮にAIが「大阪です」と出力するような場合がハルシネーションに該当しますね。間違った情報を思いついてしまったということです。
このようなハルシネーションのパターンとしては、大きくは下記の3つがあります。
- 完全な誤情報の生成:そもそも事実とは異なる情報を生成するパターン。
- 例:「日本の首都は大阪です」と回答する場合。
- 架空の引用やデータ:実在しない人物、研究、データを引用するパターン。
- 例:存在しない論文や統計を引用する場合。
- 主要部分が誤っている情報の生成:部分的には事実に基づいているが、主要な部分が誤っている情報を生成するパターン。
- 例:「東京は日本の首都であり、砂漠の気候です」と回答する場合。
それでは、次に実際の具体例に基づいて、どういう事象なのか説明していきます。
ハルシネーションの具体例
ハルシネーションはどの生成AIにおいても生じますが、私が遭遇したChatGPTでのハルシネーションを一例として挙げます。ここでは、ジオゲッサーと呼ばれる地図ゲームについて、2023年9月頃に調べたときの事例になります。なお当時使用したのは、ChatGPT 3.5です。

このように、まるで出鱈目な回答を生成しました。geyserは間欠泉の意味なのでその説明としては合っていると思いますが、geyserをジオゲッサーと読む人はいません。
ハルシネーションは何故起こる?主な原因
このようなハルシネーションが生まれる原因としては複数ありますが、大きくは下記2つが主要因だと考えています。
- トレーニングデータの質:AIのトレーニング時に使用された入力データに不正確な情報や不完全なデータが含まれていると、その影響で誤った情報を生成する可能性があります。また、Chatgptはリアルタイムで学習しているわけではないため、最新情報が不足していることでの誤りも生じえます。
- 文脈の理解不足:質問の文脈や背景情報を正確に理解できない場合、AIは不適切な情報を生成することがあります。例えば、曖昧な質問に対して文脈外の情報を持ち出して回答してしまうことがあります。更には学習していないことを回答する際にも、無理矢理分かったように振る舞い、回答することもあります。
例えば先ほどの例では、2024年6月時点、下記回答の通り正確な回答が得られています。当時よりは最近の情報もトレーニングデータとして取り込んており、関連する情報量が多くなっていることで、より正確な出力が出来るようになったものと考えられます。

文脈理解に関する影響:ChatGPTのバージョンの違いでの検証
以上から、トレーニングデータの質、文脈の理解不足がハルシネーションが起こるかどうかに影響が大きいと考えられます。文脈の理解力に関しては、ChatGPTのバージョンアップによって進歩していると考えられますので、バージョンの違い(GPT3.5, GPT4, GPT4o)によって改善がみられるのか実際に検証していきました。
後述するように、詳細な地理的情報は特にハルシネーションが起きやすいため、今回は「日本の都道府県について、面積の大きい順に10位まで列挙して下さい。」と訊くことで検証を行いました。なお、2024年6月時点の結果で、正答は下記の通りとなっています。
| 1位 | 北海道 |
| 2位 | 岩手県 |
| 3位 | 福島県 |
| 4位 | 長野県 |
| 5位 | 新潟県 |
| 6位 | 秋田県 |
| 7位 | 岐阜県 |
| 8位 | 青森県 |
| 9位 | 山形県 |
| 10位 | 鹿児島県 |
(1) ChatGPT 3.5の場合
下記が実際の生成結果となります。1位の北海道のみが正解という、正答率は1/10という惨状です。やはり、地理的な情報についてはハルシネーションが生じやすく、またGPT3.5は回答精度が低いことも分かるかと思います。

(2) ChatGPT 4の場合
こちらは1~3位と8位が正解で、正答率は4/10です。ただ、記載されている面積は全て合っているので、面積順に並べるという操作を不得手としているようですね。いずれにせよ、GPT3.5よりは改善しているものの、まだまだハルシネーションが多いという結果です。
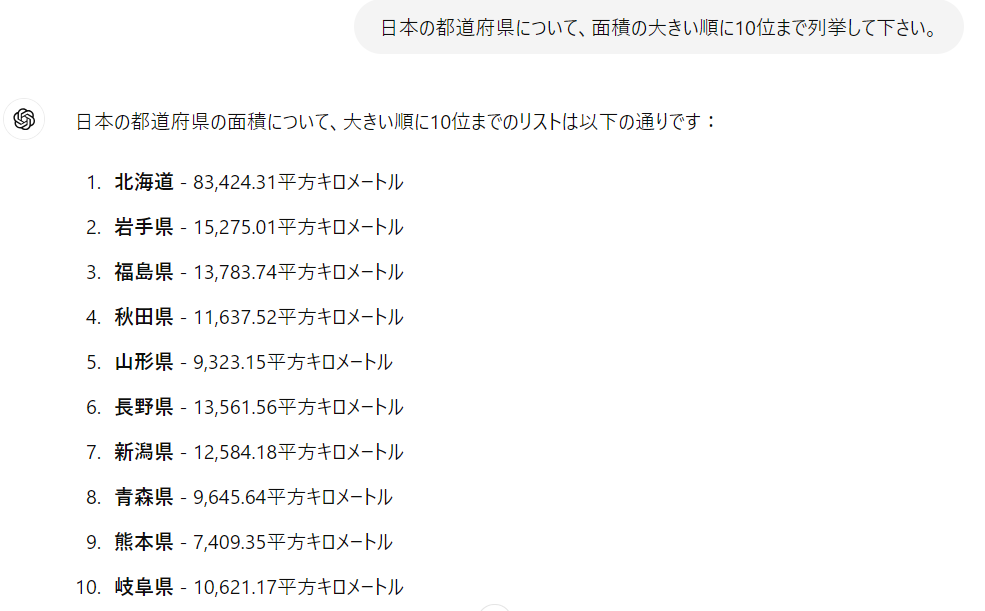
(3) ChatGPT 4oの場合
こちらについては1~8位まで正解となっており、正答率は8/10と大きく改善されていました。面積も正しいですし、順序も合っているのですが、本来9位の山形県が抜けてます。

これらの結果から、ChatGPTはバージョンアップによって誤答が大きく減っていることから、ハルシネーション対策が進んできていることが分かります。これはChatGPTの文脈を理解する能力が、バージョンアップとともに向上したためと考えられます。
トレーニングデータの質の影響:ブラウジング併用の効果
文脈理解以外の入力側の観点からすると、もうひとつのトレーニングデータの質(最新情報、多様性、信頼性)が重要です。そのため、ブラウジングする機能を併用することがハルシネーション抑制には有効です。こちらの影響についても確認していきましょう。
ChatGPT 4o (ブラウジングあり)
プロンプト中に「ブラウザで調べて回答してください」と指示することで、強制的にブラウジングさせています。結果は下記で、全問正解でした。ここまでくるとハルシネーションは起こらず、正しい回答が得られますので、ハルシネーション対策として有効だと言えます。

更に、参考までにOpenAI以外の生成AIでも同様の検証を行った結果を紹介していきます。
Gemini(Google)
何かと話題の尽きないGeminiです。こちらもGoogle作成だけあって検索を重視していると思いますが、結果としては8/10の正答率でした。これも何故か山形県が抜けてしまっていました(AIにとって山形県は影が薄いのか…?)。

Perplexity AI
Perplexity AIはAIを活用した検索システム(検索結果をAI(ChatGPT 3.5)により要約して回答する)なので、こちらも検索寄りであることから、ハルシネーションが少ないと期待しました。実際の正答率は10/10で問題ありませんでした。
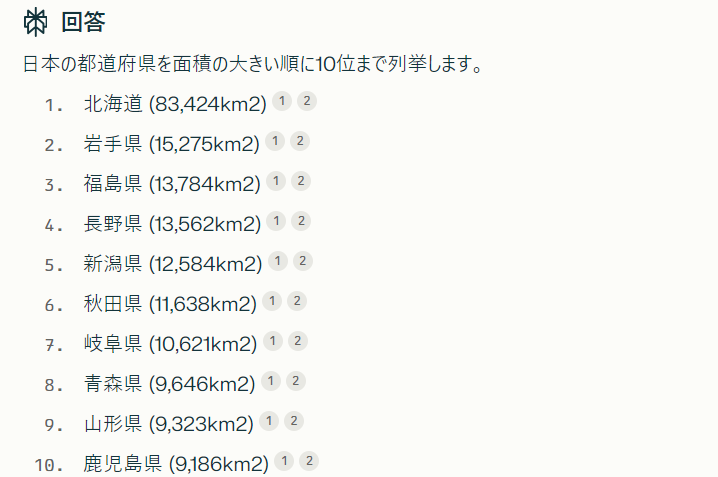
Bing Copilot
これも検索システムメインで、ChatGPT3.5を利用しているため、同様に10/10の正答率でした。画像付きで回答してくれるので、より親切ではありますね。


ハルシネーションの検証のまとめと対策
以上のように、ブラウジング機能との併用はハルシネーション対策に対してかなり有効となっています。最新情報を取り入れられるのと、情報が多角化するためだと考えられます。
ここまでの結果を表形式でまとめてみたのが下記になります。ハルシネーションの起こりやすさという観点で参考になればと思います。
| モデル | 正答率 | 備考 |
|---|---|---|
| ChatGPT 3.5 | 1/10 | |
| ChatGPT 4 | 4/10 | 面積自体は正しいが、大きい順に並べられない |
| ChatGPT 4o | 8/10 | 山形県が抜けている |
| ChatGPT 4o + ブラウジング | 10/10 | |
| Gemini | 8/10 | 山形県が抜けている |
| Perplexity AI | 10/10 | |
| Bing Copilot | 10/10 | 各都道府県の画像もあり |
ハルシネーションが起こりやすい分野は?
続いて、ハルシネーションを起こしやすい分野について説明します。というのは、一般的な知識や情報源の多いことについては、AIはハルシネーションを殆ど起こさないため、ハルシネーションの起こりやすさは知識分野に依存しています。
特にハルシネーションが起こりやすいのは、情報の正確性が重要であり、専門的な知識や複雑な知識が必要とされる分野となります。以下に、具体的な分野を挙げて説明します。
医療
理由: 医療分野は非常に専門的で複雑な知識が要求されるため、AIが誤情報を生成しやすくなっています。日々進歩も大きく、新しい研究結果や治療法が次々と発表されるため、最新の情報を把握するのは難しいことも要因です。
具体例: 診断での誤診率は8割以上だったという調査結果がある(JBpress)。
法律
理由: 法律の文書や判例は非常に複雑かつ難解であり、更に国や地域によって法律が異なることもあり、全ての法的情報を正確に把握することが難しいためです。
具体例:2023年5月にアメリカの弁護士がChatGPTを使用して裁判資料を作成した際、6つの架空の判例を生成した事例がある (Wikipedia)。
科学技術
理由: 科学技術分野も日々進歩が速く、最新の研究結果や技術情報を正確に把握するのは難しいです。専門用語が多いこともハルシネーション発生の要因になっています。
具体例:「cycloidal inverted electromagnon」という架空の現象について質問された際、ChatGPTはその現象に関する解説と架空の論文を生成した (Wikipedia)。
歴史、地理
理由: 歴史や地理に関する情報も膨大かつ、国や文化によって解釈も異なります。更には、新しい発見や研究によって従来常識が変わる可能性もあるため、ハルシネーションを起こしやすいです。
具体例:上で説明したような、都道府県の面積だったり、歴史人物の詳細な年表など。
まとめ:ハルシネーションの可能性を考慮して、情報ソースは多角化しよう!
ここまで述べてきた通り、ハルシネーションは、生成AIが誤った情報や架空の情報を生成する現象であり、特に専門性の高い情報やマニアックな内容において発生しやすい傾向があります。これを防ぐためには、最新のモデルを使用しつつ、webブラウジングなどを併用させることで、最新かつ多角的な情報源を元に結果を生成させることが重要です。
一方で、そこまでしてもハルシネーションを完全に防ぐことは困難なこともあるので、生成結果を過信せず、疑いを持つ姿勢が大事です。こういった間違いは必ずしも生成AIだけでなく、マスメディアにおいても多々起きてきたので、ネットリテラシーとして備えておくことに越したことはないかと思います。
コメント