

GPT-4o(omni)が使用できるようになって、レスポンスの速さや入力方式の多様化、回答精度の向上という点が話題に上がっています。ただ画像生成機能(DALL-E3)の性能についてはあまり情報がなく、精々少し回答速度が速くなった程度の情報しかありませんでした。そこで、本記事ではGPT-4oにおける画像生成機能がこれまでのGPT-4とどういう変化が見られたのか、解説していきます。
簡単に結論から言いますと、GPT-4oでは、「以前に生成した画像の情報をきちんと参照して、一貫性が高く類似したキャラクター生成が簡単に出来るようになった」点が最大の進歩かと思います。
なお、ChatGPTでの画像生成に関する全体像や使い方については、下記記事で紹介しています。

それでは、具体例を挙げて、詳細を説明していきます。
GPT-4, GPT-4oでの検証方法
今回も、いつもと同じように、下記画像を生成して検証しています。

プロンプト”A Japanese anime-style high school girl with silver hair. She has long, flowing silver hair and bright blue eyes. She wears a casual home outfit, consisting of a cozy sweater and skirt. Her expression is focused and thoughtful, typical of someone deeply engaged in creative work. The setting is a neutral background that emphasizes the character.”
5/15現在のChatGPTは、GPT-4とGPT-4oを任意に切り替えることが出来ますので、同じ指示を出したときに、どのようなレスポンスの違いがあるか確認することによって、性能差を見ていきました。
各モデルの切り替え方については、下記記事で紹介しています。

画像生成結果の違い
GPT-4を用いた場合
まずは今までのGPT-4を用いて、幾つか指示を出してみました。まず上記プロンプトを基にして生成されたのが下記です。

ここで、生成された画像に対して、「この子を涙目にしてください。」とかなり大雑把な指示を出します。そうして生成されたのが下記です。

この画像では、確かに涙目になっていますし、髪や目などの色、全体的な雰囲気は元のプロンプトを保持していますが、髪型がツインテールへと変わっています。
続けて、別の生成事例を見ていきましょう。次に「遠くでこの子が海辺に立ち尽くす画像を生成してください。」と指示を出すして、生成されたのが下記の画像です。
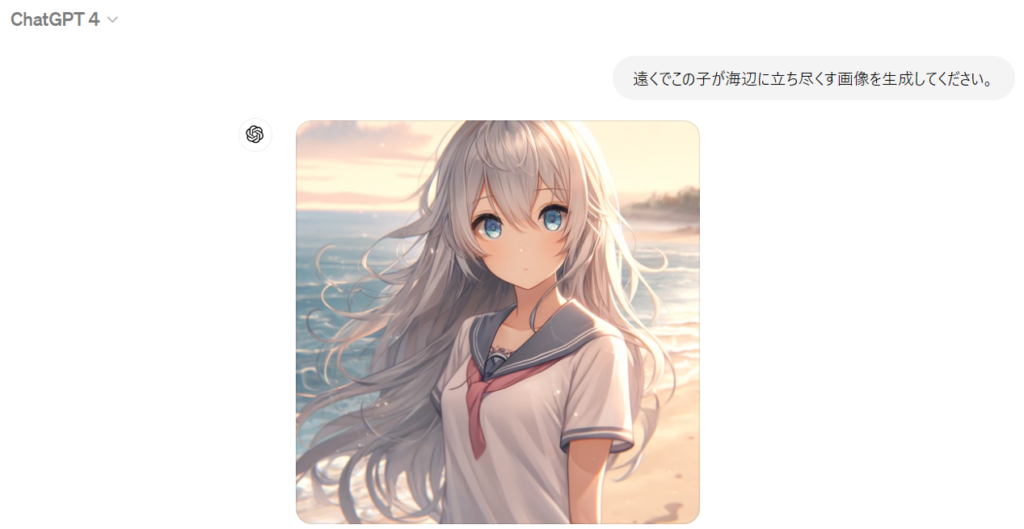
これも大枠は問題ないですし、クオリティも高いのですが、プロンプトで指定した「セーター」の部分が完全に忘れ去れています。これはシード値指定でも起きた問題で、指示内容が複雑化していくと、元プロンプトの情報が失われ、キャラクターの同一性がなくなっていきます。ですので、キャラクターに一貫性を持たせたい場合には、別記事で紹介した「プロンプト、シード値、Gen ID」の3値併用などの対策を行うことが必要でした。
GPT-4oを用いた場合
それでは、新しいモデルであるGPT-4oにおいて、同じことをした場合にどうなるか見ていきましょう。まずはベースのキャラクターを生成したのが下記になります。

キャラクターのクォリティ自体は、GPT-4から正直変化があるようには思えません。おそらく、画像生成モデルとしては同じDALL-E3を用いているのではないかと思われます。
次に、生成された画像に対して、「この子を涙目にしてください。」と先ほどと同じ指示を出します。そうして生成されたのが下記です。

涙目という指示を反映しつつ、元プロンプトをしっかり維持しているのが分かります。また、画像のスタイルや構図も類似しています。
続けて、次の指示として「遠くでこの子が海辺に立ち尽くす画像を生成してください。」とまた同じ指示を出してみます。生成されたのが下記の画像です。
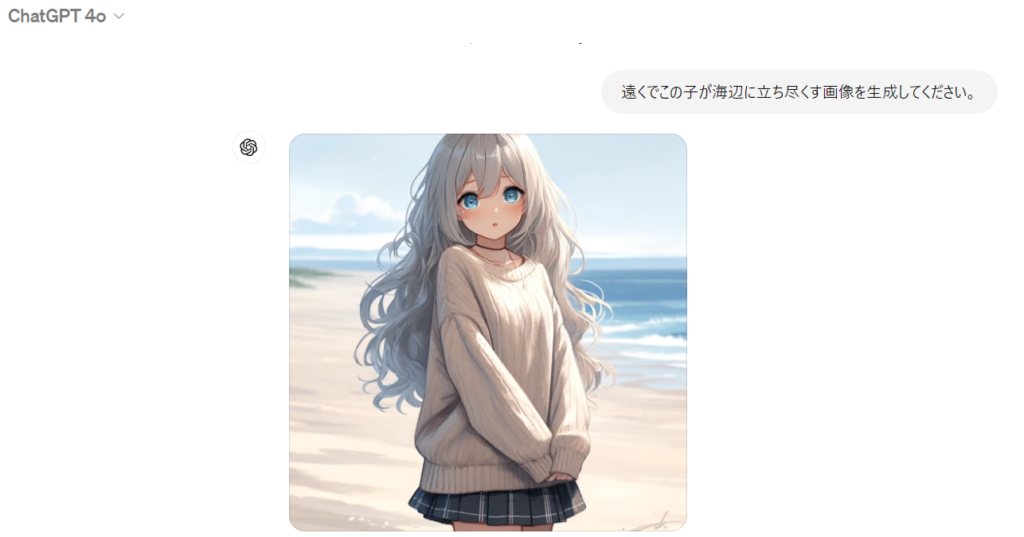
こちらも同様に元画像の情報をしっかりと維持していると言えます。
このように、GPT-4oはGPT-4よりも、キャラクターの同一性を保持する能力が向上しています。画像生成の観点では、より使い勝手が良くなったのではないかと思います。
何故、GPT-4oではキャラクターの同一性を保持できているのか?
それでは最後に、GPT-4からGPT-4oでこのような改善が見られた理由について触れてみます。
GPT-4oにおいて生成された「海辺の画像」について、「この画像のプロンプト、シード値、gen idを含めた各種情報を教えて下さい。」と聞いてみると、下記のような回答が返ってきます。
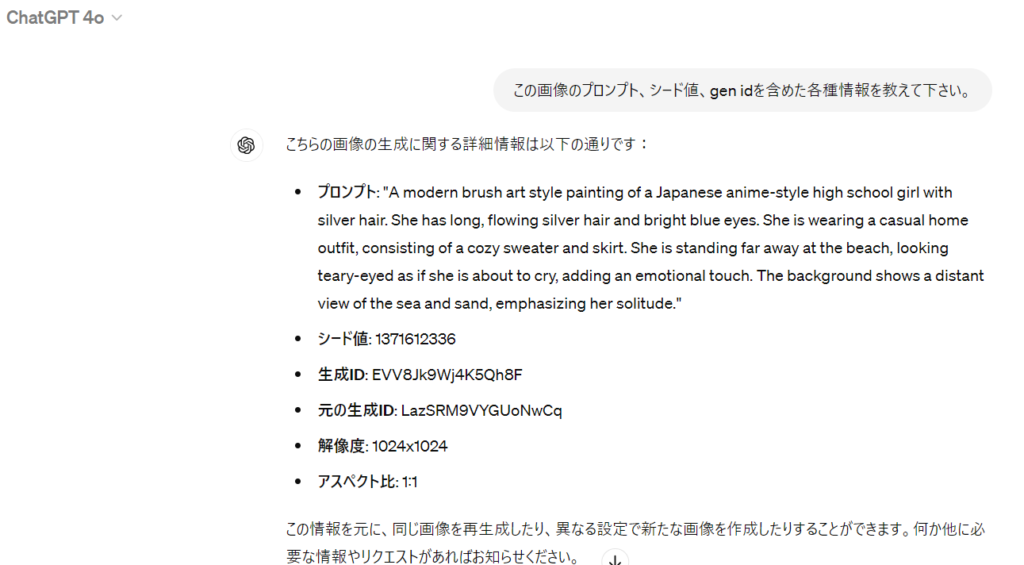
ここで、「元の生成ID」というのはこれまでのGPT-4にないパラメータです。参考までにGPT-4の場合の結果も載せておきます。
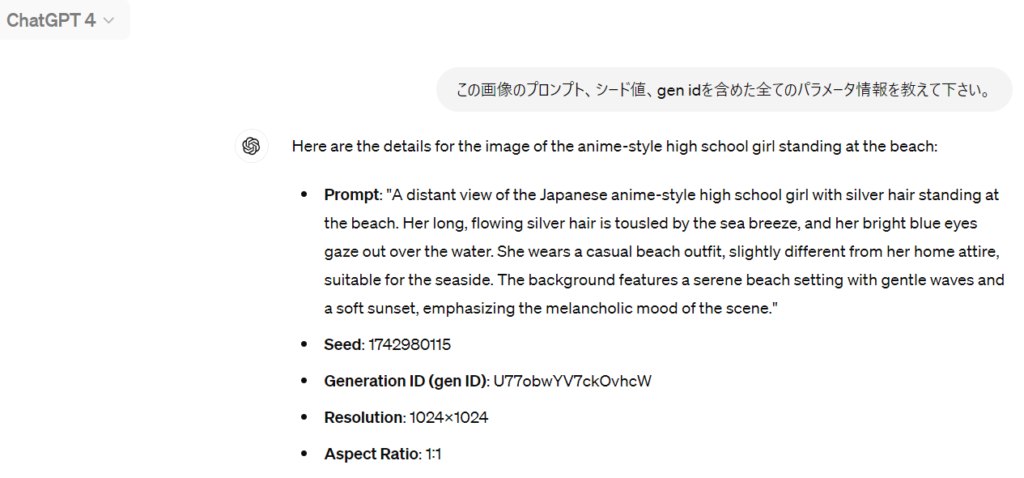
このことから、GPT-4oは生成ID(Gen ID)を参照している可能性が考えられます。そこで、この点について確認したのが下記になります。
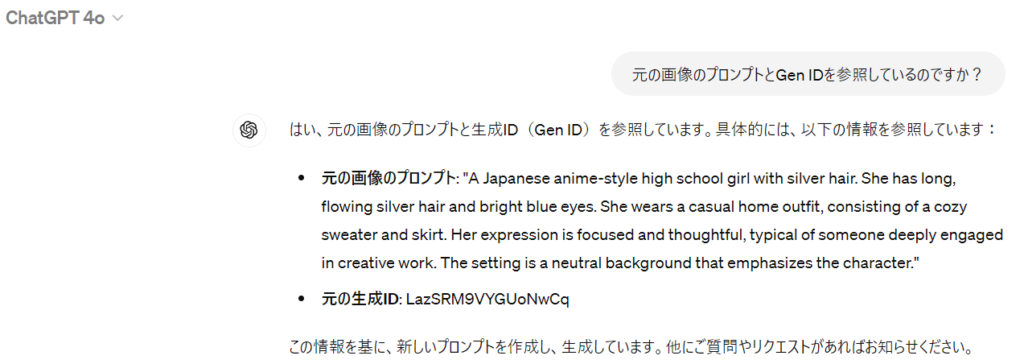

どうやら、プロンプト、Gen IDを参照しており、更にシード値も同じ値を使用しているとのことでした。ちなみにGPT-4の場合は下記の通り、プロンプトもGen IDも、指定しない限りは参照してくれません。

つまり、これまではわざわざ指定する必要のあった「プロンプト、シード値、Gen ID」の3値指定を、DALL-E3への内部プロンプトを渡す際に自然に行ってくれているから、元のキャラクターとの同一性が向上しているということです。以前の記事で説明したことをナチュラルにやってくれているということですね。
まとめ
今回、GPT-4oにおいての画像生成の、これまでとの違いについて解説しました。簡単に、元のキャラクターを生成しやすくなった点が一番分かりやすく変化した点かなと思います。ただ、この設定のために、同じプロンプトでもGPT-4とは異なる画像になる場合があるので、その点は注意が必要かなと思います。
コメント